这是我最近在团队内做的一个关于 Git 的分享,反响还不错,故用此文记录。

前言

首先,本文假设你已经对 Git 有了初步的认知:
- 理解 Git 在本地的三种工作区域:Git 仓库、工作目录和暂存区域;
- 熟练操作
pull/push/branch/checkout/commit/ … 常见指令;
但是:
- 希望能够进一步了解 Git 的一些基本原理;
- 偶尔会遇到与预期不一致的现象,掉入坑中。
如果你已经熟读 Pro Git 等相关书籍、熟练使用各种底层命令,甚至有 Git 相关工具链的开发经验,那本文可能不太适合你。
接下来将分为两大主题,文件系统与命令操作:
- 文件系统主题将带领大家去理解 Git 的存储模型,我们的文件、commit 等信息是如何存储的;
- 命令操作主题将针对我们最常用的两个命令
merge和rebase去解释它们是如何工作的。
文件系统

Snapshot-based, not delta-based
不知道大家有没有经历过不使用版本控制的项目,在大学期间我做第一个外包项目的时候,虽然已经了解了 Git 的基本使用方式,但是完全没有工程经验,不知道源代码版本控制的意义所在,没有选择使用版本控制,然后就吃了大亏。在开发初期还好,但在联调和交付阶段,细节变更频繁发生,而我应对变更区分版本的方式是复制文件夹,给文件夹命名版本号来区分版本,缓解了问题。
在和队友复盘的时候,我们深刻的意识到了版本控制的重要性,从那之后不管大小项目,都会使用 Git 来管理源代码版本。
当然我讲这个故事的目的并不是想说明版本控制的意义,而是想由此引出一个问题,如果你来实现一个版本控制工具,你会如何设计最核心的部分:存储?
有同学的第一反应可能会是和上面我的做法类似,把整个项目存一份,打上版本号;想的更深一点的同学,可能会想,我只存每次的变更,每次切换版本的时候将变更串起来,得到文件,这样是不是也行?
这其实是版本控制工具文件系统实现的两种思路:基于快照(snapshot-based)和基于差异(delta-based)。那么,已经知道答案的同学不要说出答案,大家再猜一猜,Git 是基于哪一种呢?
可能在平时提交 commit、merge request 等变更行为之前,大家都会习惯性的去看一下 diff,也会对照 diff 进行 Code Review,这很容易给人一种错觉:Git 是基于差异的,但实际 Git 是基于快照的。

基于快照的优势在于,因为每个版本的文件都是直接保存的,可以更简单的实现快速切换版本,更易于实现分布式的特性(例如 patch),而带来的劣势在于存储空间会明显占用更多,一个文件即使改动一个字符也需要再单独存一份,当然 Git 也适度的做了一些优化,包括主动的和被动的(zlib 压缩、pack);
相比之下,基于差异的优势则是存储空间占用极低,几乎接近极限,而劣势则是如果想要做到和基于快照一样的切换版本速度,需要设计更复杂算法和逻辑(例如借助索引将版本切换时间降到常数级别)。
这里不去过多探讨两种方式的差异,因为在工程中这是个取舍的问题。我们需要了解的是 Git 使用了基于快照的方式存储信息,这样便于理解接下来的内容。
Objects

接下来我们一起来对 Git 文件系统的具体实现探个究竟。
blob object
接着刚刚如何实现一个版本控制工具的问题,现在我们已经确定了用基于快照的思路,像我那样每个版本把整个项目打包一份肯定是不太合适的,每个版本之间一般只会变更一小部分文件,那么如何尽可能的减少存储?大家应该会想到:没有发生变更的文件只存储一份,在各个版本之间只保存对这个文件的引用,使用过对象存储服务的同学应该会想到对象存储,使用 k-v 来存储文件,key 使用一个唯一值,value 则是文件。
Git 的核心部分正是这样一个简单的键值对存储,key 是存储对象加一些元数据一起做 SHA-1 校验运算得到的哈希值,value 是压缩过的数据对象。注意我这里的说法是对象而非文件,因为在 Git 的键值对存储系统中,数据对象(blob object)是对象(Objects)类型的一种,为什么只是一种呢?
tree object
在上述的存储系统中,我们存储一个文件后,得到的只有一个哈希值作为 key,这只解决了存储文件的问题,并没有解决文件名存储的问题,要将文件和文件夹组合起来,我们还需要一个用树对象(tree object)来存储这种关系,所以在 Git 中,项目文件的存储形式可以简化如图中所示。
commit object
现在有一些树对象,分别代表了我们整个项目不同版本的快照。然而问题依旧:若想重用这些快照,你必须记住所有的 SHA-1 哈希值。 并且,你也完全不知道是谁保存了这些快照,在什么时刻保存的,以及为什么保存这些快照。 而以上这些,正是提交对象(commit object)能为你保存的基本信息。
上述这三种主要的 Git 对象——数据对象、树对象、提交对象——最初均以单独文件的形式保存在 .git/objects 目录下。
SHA-1 哈希值的长度是 40 字符,.git/objects 目录下可以看到又做了一层以 2 字符命名的子目录,子目录下的文件名长度都是 38 字符,前面的 2 字符加上文件名的 38 字符就是 SHA-1 哈希值。
多提一嘴,Git 这样做的意义主要在于优化查找速度,Git 可能跑在各种各样的操作系统文件系统之上,有的文件系统同目录下文件过多会导致查找缓慢(基于链表的文件查找时间复杂度为线性,查找速度随文件数量增长),哈希的均衡性相当于把文件打散到 16*16=256 个桶中,降低了线性的系数。
可能大家会想,如何验证你说的是真的呢?在验证之前,我们需要先了解一些不太常用的 Git 命令,他们将会帮助我们去做验证。
由于 Git 是一套完整的版本控制系统,而不是纯粹的面向用户,所以它还包含了一部分用于完成底层工作的命令。 这些命令被设计成能以 UNIX 命令行的风格连接在一起,可以与脚本配合完成一些工作。 这部分命令一般被称作「底层(plumbing)命令」,而那些更友好的命令则被称作「高层(porcelain)命令」。
以 Vue3 的仓库为例,g 是 git 的 alias,cat-file 可以打印出 SHA-1 值对应的对象信息, master^{tree} 语法表示 master 分支上最新的提交所指向的树对象,可以看到文件夹的类型是 tree,文件的类型是 blob:
1 | ➜ vue-next git:(master) g cat-file -p master^{tree} |
我们进一步的去查看 tree,会发现它是类似刚刚的树状结构,保存了文件夹中的文件关系:
1 | ➜ vue-next git:(master) g cat-file -p aab9fcef4b707da87170027ffc23610fc36e8106 |
而查看 blob 则会直接打印出文件内容:
1 | ➜ vue-next git:(master) g cat-file -p f5a1bdcdd2daf271a87314a475c36ca723c0b499 |
这是文件系统读的方式,同样我们还可以借助 hash-object 写入 blob 对象,write-tree 将暂存区写入一个 tree 对象等等,通过底层命令实现 commit,这里不去深入讲解,上述内容已经足够我们对 Git 文件系统有一个大致的了解,如果不是做 Git 相关工具的开发没有太大深入必要。
tag object
Git 中的第四种对象:标签对象(tag object)。Git tag 分为两种,轻量(lightweight)标签和附注(annotated)标签。轻量标签和分支相似,下面会分析轻量标签的存储形式;而附注标签和 commit 更相似,标签对象包含标签创建者信息、日期、注释信息和一个指针,主要的区别在于,标签对象通常指向一个提交对象,而不是一个树对象。
当然为了解决快照占用空间过大的问题,Git 设计了自动垃圾回收策略,一般 .git/objects/ 目录下的对象是以松散的方式存放的,但当这些松散对象的个数超过 7000 时,Git 会自动进行压缩,形成 pack 文件,当 pack 文件多于 50 个时,Git 会把多个 pack 文件再压缩成为一个 pack 文件。
Git 也可以手动触发垃圾回收:git gc,还可以设置自动垃圾回收策略的参数,例如刚刚的 7000 限制是个魔术数字,可以通过 gc.autoPackLimit 修改。
Refs
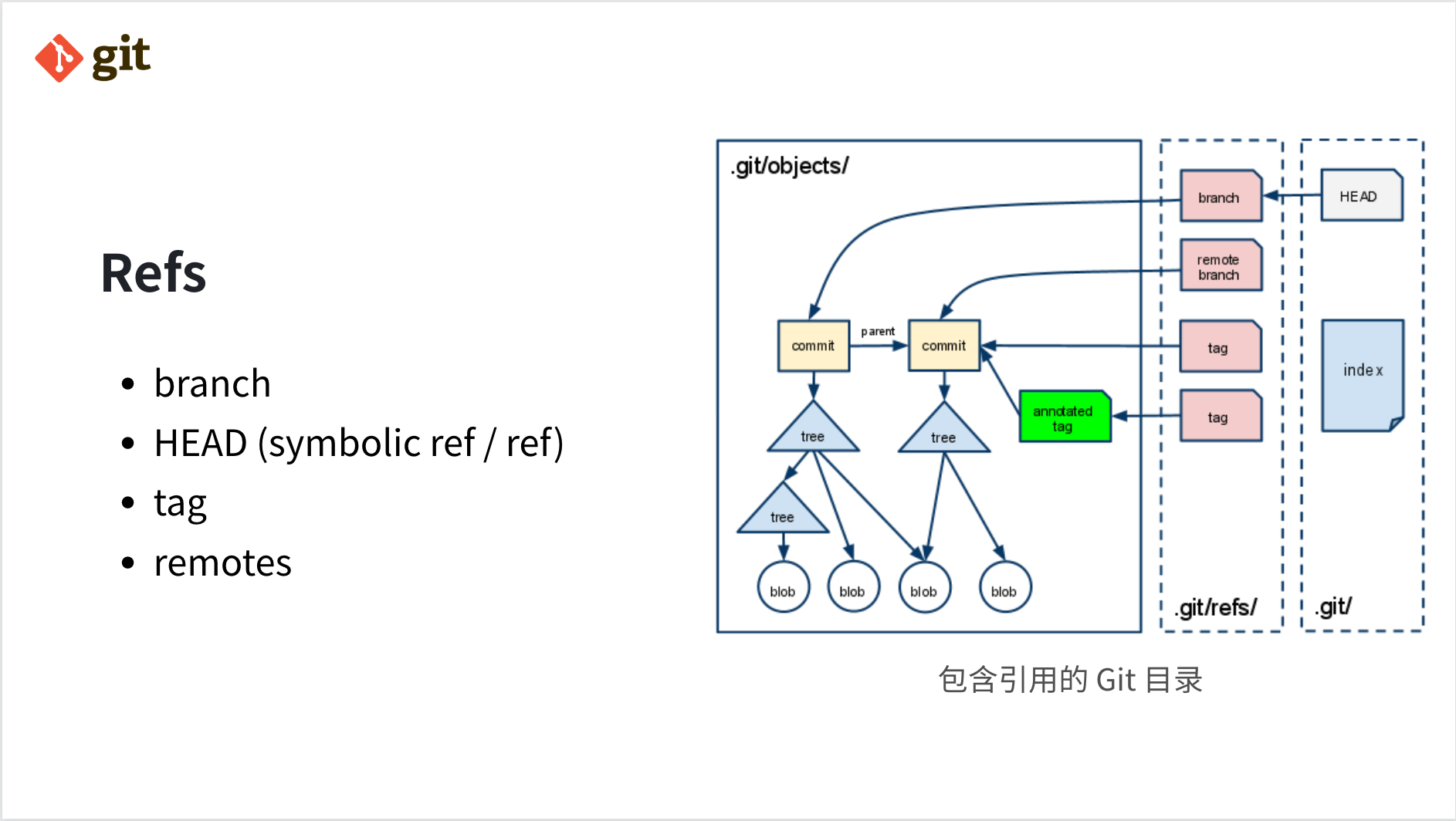
我们可以通过一次 commit 的 SHA-1 值来查看它的内容,但是记住这个哈希值显然是不现实的,应该把这个哈希值存起来,用一种更简单的方式记住它,这种方式就是「引用(refs)」。我们可以在 .git/refs 文件夹中看到这些存储了哈希值的引用文件,随意打开一个一个仓库的 refs 目录,HEAD / branch / tag / remotes 在这里一览无余。
branch
1 | ➜ vue-next git:(master) cat .git/refs/heads/master |
可以看到分支 ref 文件存储了其对应的最新的 commit SHA-1,我们完全可以修改这个 SHA-1 来改变所指向的 commit,但是不建议这么做,使用 git update-ref 是更安全的做法。
HEAD
但 Git 还需要一个记录当前在哪个分支的文件,这就是 HEAD,正常情况下它是一个「符号引用(symbolic ref)」,是一个指向了引用的指针:
1 | ➜ vue-next git:(master) cat .git/HEAD |
和 ref 文件相似,我们可以修改这个指针来改变当前所在的分支,但也有一个更安全的命令 git symbolic-ref 可以使用。
注意在 Git 中,如果你切到一个指定的 commit,也就是「detached HEAD」状态下,HEAD 文件的内容就变成了 ref,存储这个 commit 的 SHA-1 值:
1 | ➜ vue-next git:(master) g checkout c36941c4987c38c5a9 |
当然一般很少会进入这种状态,这种状态下提交的 commit 除非记住 SHA-1 值,否则很难找回这些 commit 记录,这些 commit 会变成 dangling commit,没有分支指向它们。
tag
上面我们提到 tag 分为两种(轻量标签和附注标签),并分析了附注标签,这里我们再来分析轻量标签:轻量标签和分支相似,ref 文件中存储着对应 commit SHA-1。
remotes
远程引用(remote ref)与分支引用基本相似,其指向了最近一次与服务端通信时所知晓的远端分支对应的最新 commit SHA-1:
1 | ➜ vue-next git:(master) cat .git/refs/remotes/upstream/master |
与分支引用的差异在于,远端引用是只读的,虽然我们可以 checkout 到远程引用,但 HEAD 不会指向这个引用,而是进入 detached HEAD 状态,指向这个引用所对应的 commit,在之后所做的 commit 都不会去更新远端引用。
综上,一个 Git 仓库内部的引用和文件关系大致如图所示,图中的 index 是暂存区域,这里不去展开讲了。
到这里 Git 文件系统部分的讲解就结束了,接下来是命令操作的讲解。
命令操作

在准备分享内容的时候,一开始我计划设计一个章节来讲 Git 工作流,但发现常见的工作流涉及到的大多是文件系统原理和一些基本操作,上面我们已经讲过文件系统原理,这里与其讲工作流,不如讲讲最常见的操作 merge 和 rebase,理解了它们之后工作流只不过是灵活的组合形式。
merge
merge 是一个比较常用的命令,很多时候使用起来比较简单,但有的时候却会有一些不符合直觉的现象。
Fast-Forward Merge:快进式合并
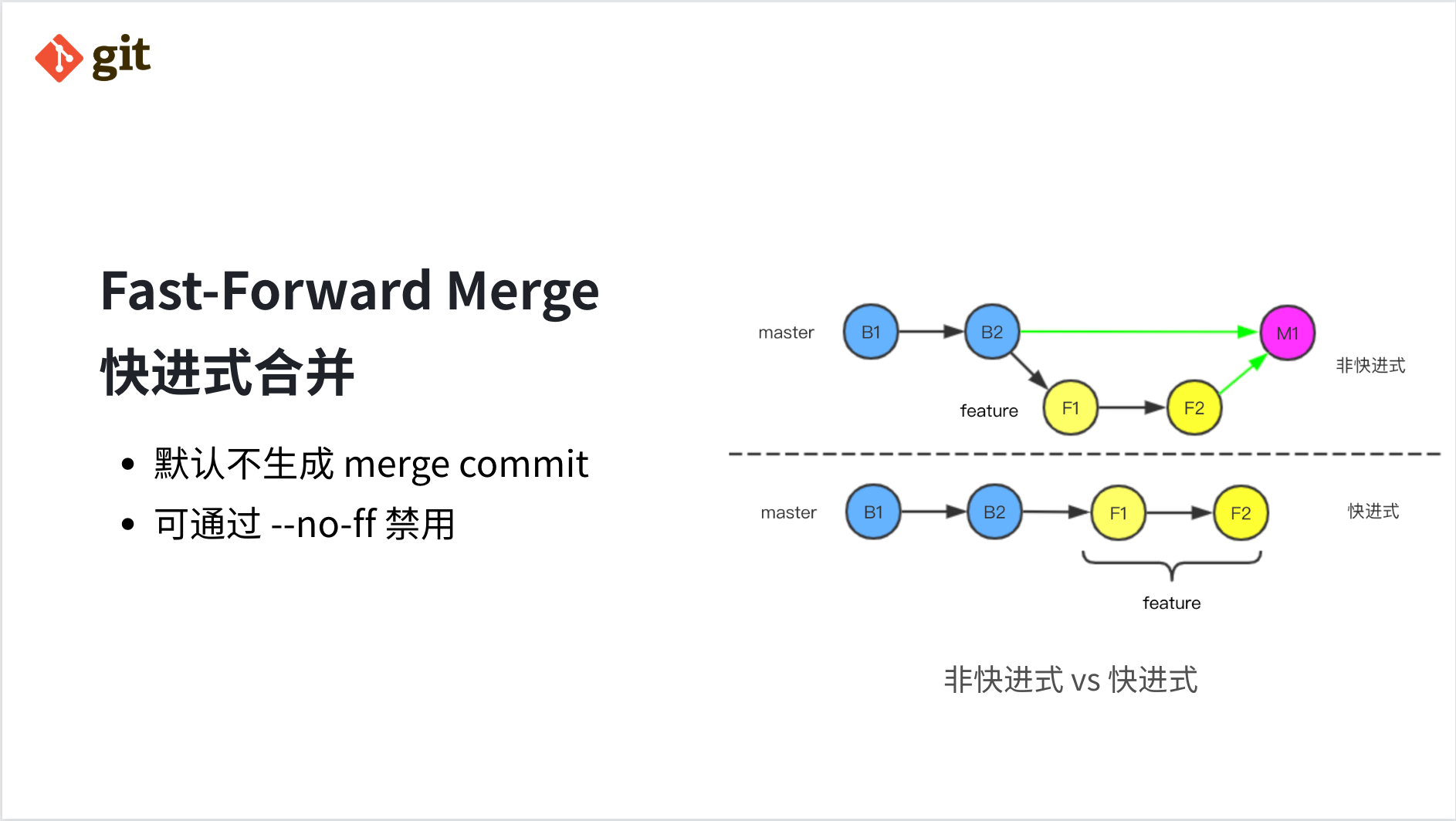
当合并的两个分支满足祖孙/父子关系时,Git 默认会使用快进式合并,最常见的场景是 pull,pull 的本质是 fetch + merge,由于一般在执行 pull 的时候远端分支相对本地分支是快进的,Git 可以直接合并,默认情况下不会产生 merge commit,但也可以通过参数 --no-ff 来禁止快进式合并。
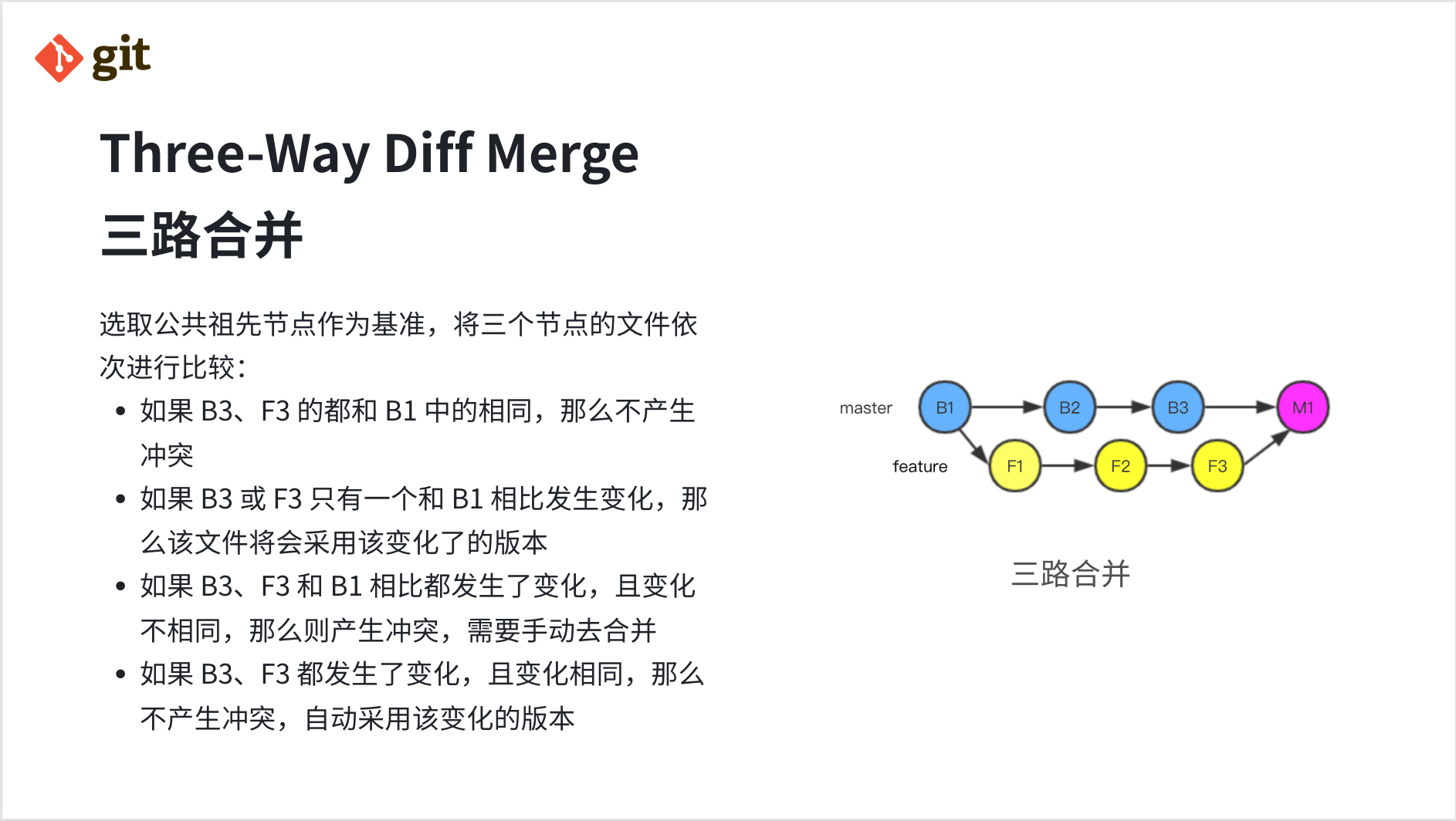
Three-Way Diff Merge:三路合并
上面我们讲到 Git 是基于快照的,每一个 commit 中都有全量的项目文件,所以在 merge 时,Git 不会使用那些中间的 commit,只去关注最新的 commit,但这还不够:
如上图所示,我们要把 feature 分支合入 master 分支,假如 master 分支只修改了文件 X,feature 分支只修改了文件 Y,在合并的时候两者是不应该产生冲突、应该将修改合在一起;但是如果我们使用两路合并算法,只去对比当前分支与目标分支的最新 commit 即 B3 与 F3,X 和 Y 都是不一致的,需要用户介入选择处理,体验会非常糟糕。
所以 Git 使用了更智能的三路合并算法,选取当前分支节点 B3 与目标分支节点 F3 的公共祖先节点 B1 作为基准(base),将这三个节点的文件依次进行比较:
- 如果
B3、F3的某个文件和B1中的相同,那么不产生冲突; - 如果
B3或F3只有一个和B1相比发生变化,那么该文件将会采用该变化了的版本; - 如果
B3、F3和B1相比都发生了变化,且变化不相同,那么则产生冲突,需要手动去合并; - 如果
B3、F3都发生了变化,且变化相同,那么不产生冲突,自动采用该变化的版本。
也许有同学会想,为啥解冲突时,我看到的只有当前节点与目标节点的差异,看不到公共祖先节点,这看起来像是两路合并?这是因为 Git 存在这一个配置项 merge.conflictStyle ,且该配置项默认值为 merge,可以将其设置为 diff3,这样之后看到的解决冲突界面就会出现祖先节点的文件内容。
Recursive Three-Way Diff Merge:递归三路合并
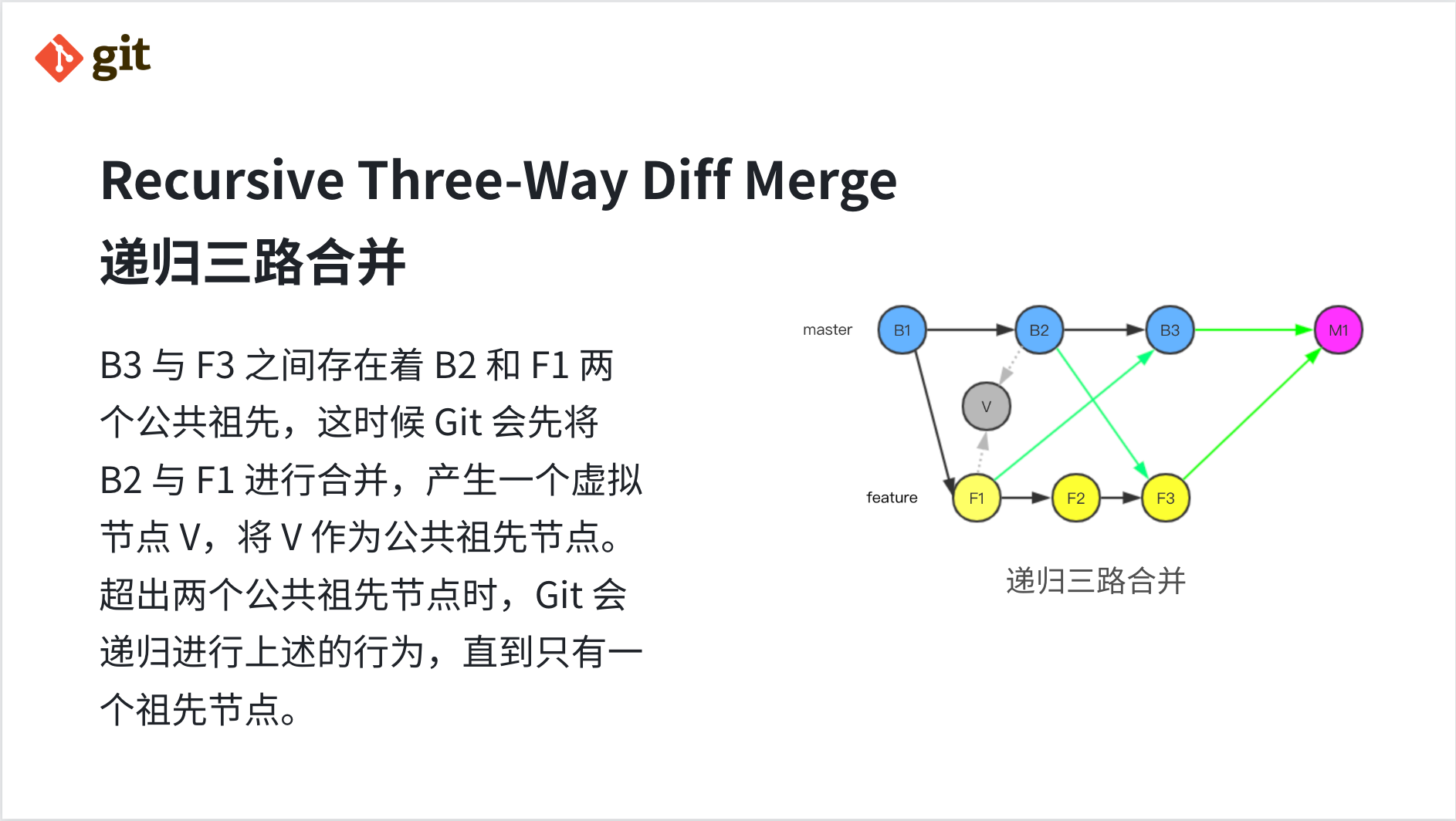
有时候我们的场景可能没有上面那样简单,当前分支节点与目标分支节点之间可能存在多个公共祖先,先举一个有两个公共祖先的例子。
如图所示,B3 与 F3 之间存在着 B2 和 F1 两个公共祖先,这时候 Git 会先将 B2 与 F1 进行合并,产生一个虚拟的节点 V,将节点 V 作为公共祖先节点。
两个公共祖先节点的情况这样处理,超出两个的情况也就很类似了,Git 会递归进行上述的行为,直到只有一个祖先节点,这也是为什么叫「递归三路合并算法」。
Git 提供了一个底层命令 git merge-base,可以用它来查找两个 commit 的公共祖先节点:git merge-base <commit1> <commit2>;另外在 UNIX 上还有一个 diff3 的命令,可以对三个文件进行三路 diff,这里就不再去展开讲了,大家可以自己进行尝试。
三路合并来带的陷阱
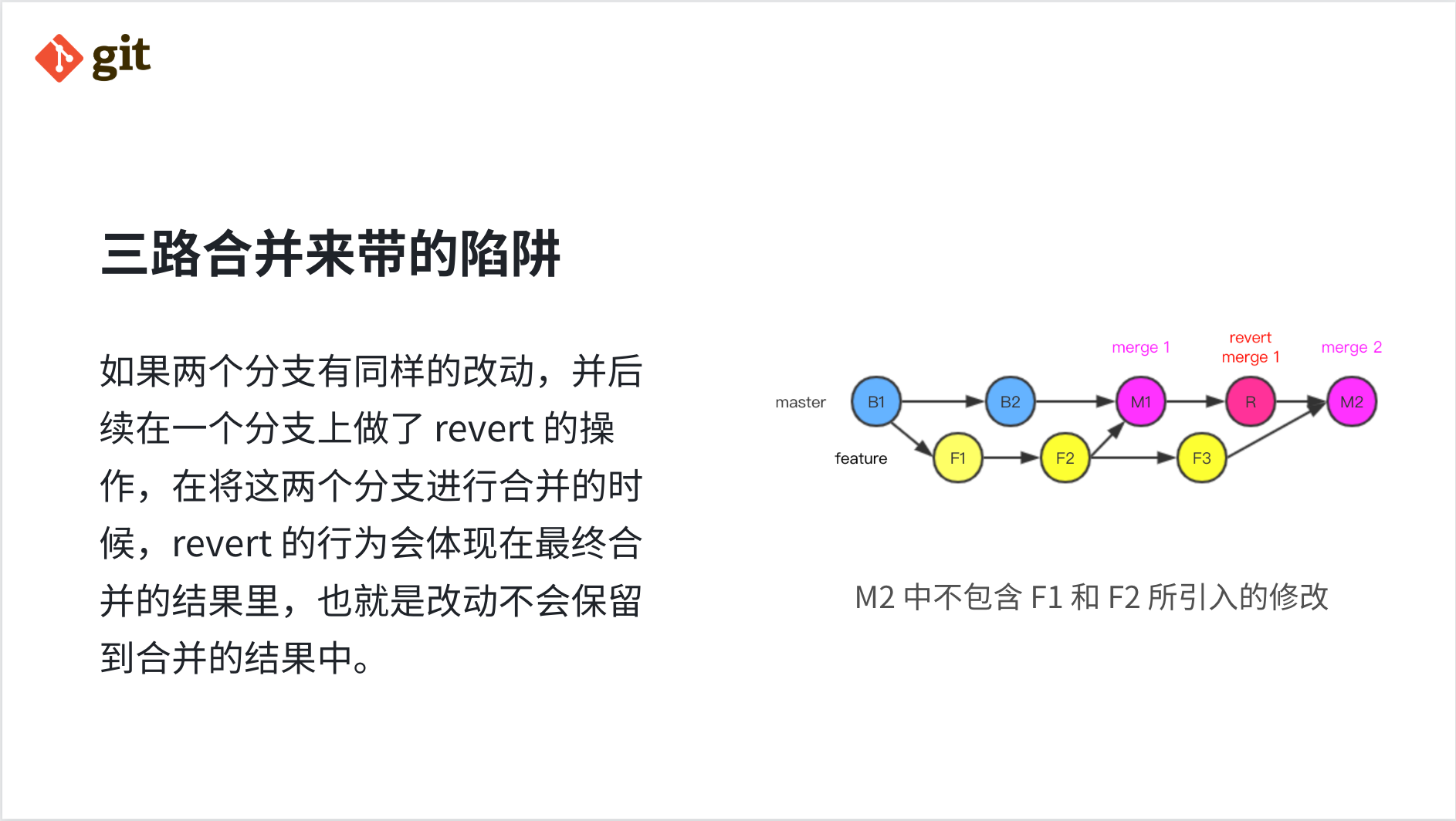
如果两个分支有同样的改动,并后续在一个分支上做了 revert 的操作,在将这两个分支进行合并的时候,revert 的行为会体现在最终合并的结果里,也就是最初的改动不会保留到合并的结果中。
最常见的场景是,当一个特性分支在开发过程中被误合入主分支后,在主分支上 revert 了这个 merge commit,在特性开发完成再次合入主分支时,会发现上次合入的代码都丢失了。我在使用 Git 的过程中经历过几次这样的情况,也有其他的小伙伴遇到过,甚至有因为丢失代码出了线上事故的真实案例。
通过 git merge-base R F3 我们会发现第二次 merge 的最近公共祖先节点是 F2,而已经不再是 B1,第一次 merge 改变了特性分支与主分支最新节点之间的最近公共祖先节点,根据三路合并算法的原理,F1 F2 的代码在公共祖先节点 F2 以及 F3 上是一致的,那么在主分支上所做的 revert 修改将会被带入最终的 merge 2。
针对这种情况如何解决?复制粘贴代码的做法是强烈不建议的,复制粘贴很可能会再一次搞丢代码,我想到的安全的做法有两种:
- 在主分支上再次
revert R(revert revert 套娃操作); - 通过
cherry-pick将F1和F2一起pick到主分支上。
rebase
基本用法
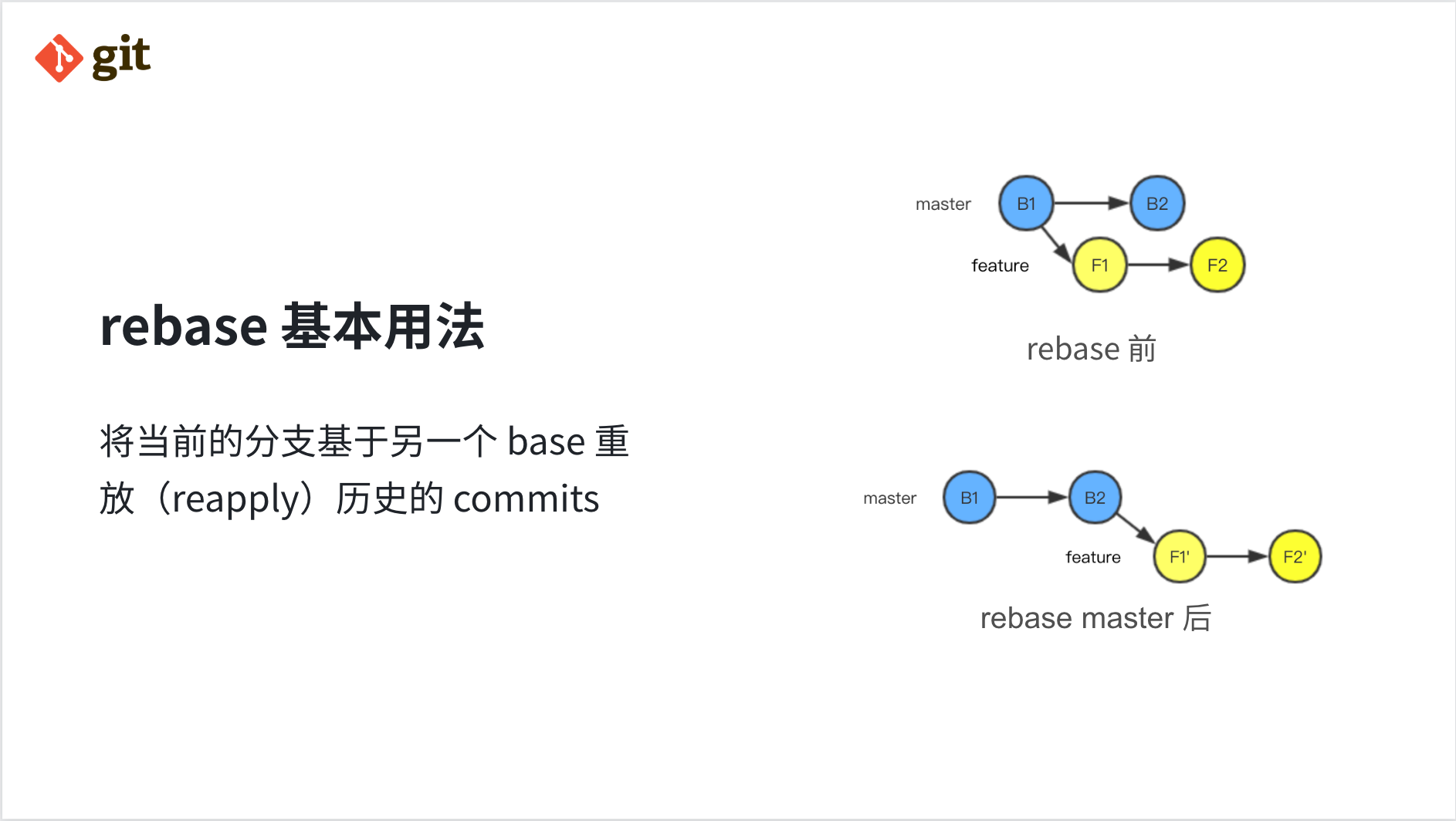
很多时候大家对 rebase 的认知是可以帮忙引入其他分支的改动并解除冲突,也会和 merge 进行对比,因为这种场景下往往 merge 也可以达到类似的效果,但实际 rebase 的使用场景更广泛一些。
刚刚说的常见场景是将当前的分支基于另一个 base 重放(reapply)历史的 commits,以 git 文档中的例子进行解释,当前我们有两个分支,master 与 feature,并且当前我们在 feature 分支上,在执行 git rebase master 后,将变成图中下方所示。
通常我们会使用它来将上游分支(一般是 master)上的特性引入到目标的分支上(当前工作的特性分支 / bugfix 分支),已保持当前的工作分支包含了想要的特性,并且与目标分支不存在冲突。
rebase 的原理
Git 先将所有在目标分支但不在上游分支的 commit 保存到一个临时区域,这些 commit 和 git log <upstream>..HEAD 的结果是一样的;接着将目标分支的指针设为和上游分支一致,再从刚刚的临时区域将 commit 按照顺序一一的进行重放。
每一次的 commit 重放都是一次三路合并:重放 F1 时,选择 F1 和 B2 的公共祖先节点 B1 作为 base;重放 F2 时,选择 F2 和 F1’ 的公共祖先节点 B1 作为 base;在 commit 的数量更多的情况下依次类推。
修改当前分支的历史记录

在 Git 中并不存在一个专用的修改历史的命令,但我们可以借助 rebase 来修改历史。这里 rebase 的上游可以不只是其他的分支,也可以是当前分支的历史记录节点,配合 rebase 的交互模式,可以实现重写当前分支的历史:修改 commit、合并 commit、拆分 commit、调整 commit 顺序等等。
实际使用也比较简单,可以看下 Git 文档,很容易上手,相关的文章也非常多,这里就不去赘述。
如何判断我是否可以重写历史?
- 已经进入多人协作的公共分支,绝对禁止重写历史:
- 如果远端分支禁用了
push --force,无法修改远端的记录,会导致自己与远端不一致; - 如果
push --force强制修改远端的记录,则会导致其他人的本地与远端的不一致;
- 如果远端分支禁用了
- 想要修改的历史记录只在本地,或者对应的分支只有自己在使用,远端允许
push --force,可以重写历史。
如何判断我是否应该重写历史?
实际上社区存在两种观念:历史记录需要被尊重不应该被修改 vs 历史应该更清晰便于查阅,在实际的工程中,甚至存在着两种极端:
- 禁止
rebase,远端完全禁止force push,虽然无法禁止对于未提交的 commits 进行重写,但是一旦提交的 commits 就不再可以被变更了; - 除了使用 GitLab 的 MR 做 Code Review 的代码合入之外,禁止手动
merge,如果需要引入特性提前排除冲突,必须使用rebase/cherry-pick。
这里不去探讨应该认可哪种观念,但客观来讲,正确、适度的使用 rebase,可以帮助我们得到更清晰的 commit log 和 branch graph,便于之后的查阅 log / revert / cherry-pick。

问答环节

1. 最佳实践
记最佳实践不如理解本质。分享我的一些个人习惯,算不上最佳实践:
- 借助
rebase,尽量保证commit的原子性,便于revert/cherry-pick - 如果
feature分支只有我一个人在使用,且没有禁用 force push,则经常rebasemaster - 尽量不拿子分支去
merge祖先分支,保证分支线清晰 - 除非很明确目的,否则在
merge时不做squash - 配置
alias,少打一些字母,减少出错率 - 善用
stash,保存未完成的工作
2. 误提交的大文件,从 .git 历史记录中完全移除的方法
commit 的链式结构保证了无法单独修改某一条而不影响后续的记录:
- 如果是多人合作的仓库,不建议这样操作
- 如果是单人使用的仓库且可以强制
push,可以考虑。
具体做法:借助 filter-branch 将涉及到的 commit 全部重写,再执行垃圾回收,参考 Pro Git 10.7 章节 Removing Objects 部分。
3. stash 没法将新增的文件一起存起来
git stash -u 即可,-u 表示带上未被 tracked 的文件。
还有一部分提问这里记不太清了,如果有其他问题欢迎在评论区讨论。